AzeGPT - The first Azerbaijani Large Language Model
Aug 8, 2023

NurAI Azeri Large Language Model — An AI Assistant That Speaks Our Language
Problem Statement:
Existing language models like GPT-3 and GPT-4 have shown the power of large neural networks for generating human-like text and conversing naturally. However, they were trained predominantly on English data, with limited Azerbaijani content. This results in inconsistent performance when applied to the Azerbaijani language and culture.
For example, while GPT-3 was trained 175 billion parameters, which is roughly 700GB of memory of text data, likely less than 1% of that was in Azerbaijani. Even the best AI assistants today cannot hold a natural dialogue in Azeri or provide locally relevant information to Azerbaijani users.
Our Solution:
NurAI Azeri LLM (easier name in the works) aims to fill this void. We are developing a state-of-the-art language model fine-tuned on Azerbaijani content—spanning literature, internet resources, academic texts, and more — to provide a truly localized AI assistant. This isn't just a translation of global models; it's an AI bred in the landscape of Azerbaijani culture and language.
Natural conversational ability in Azerbaijani language
Locally relevant knowledge of Azerbaijan's history, culture, geography, etc.
Ability to understand and respond to Azerbaijani slang, context, etc.
Imagine having a conversation with a friend who knows a lot about many subjects—sports, the latest news, Azerbaijani history, you name it. A Large Language Model (LLM) aims to be that "knowledgeable friend" but in a digital form. You can ask it questions, and it will generate responses in real-time, almost like you're chatting with a human.
So in the case of LLMs, they are good at finding patterns, and they are as good as the training data you feed them. Training on more data == more $money$ spent. That was a gross oversimplification — for the record.
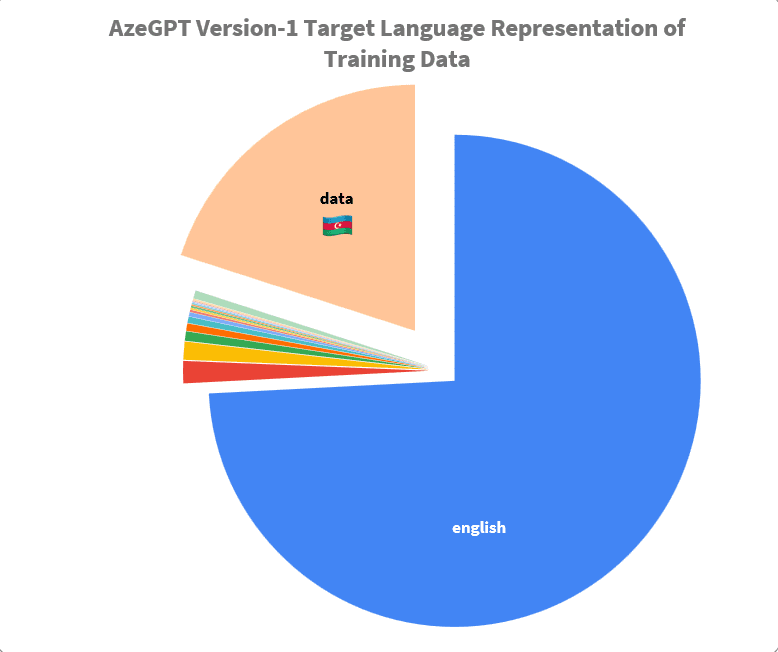
Let's look at GPT-3's brains' memory, and look at the languages spoken in its data.

Notice that tiny orange slice labeled 'Other'? Azerbaijani is part of that minuscule slice, making up less than 1% of the total data in these models.
We aim to teach the LLM more about us, and so then it will be 'closer' to us if we speak in 'human' terms.
Feed it some Wikipedia articles in our language, some of our textbooks and library archives, some news articles and perhaps a human interaction dataset — and we'll get something like this, InshaAllah:
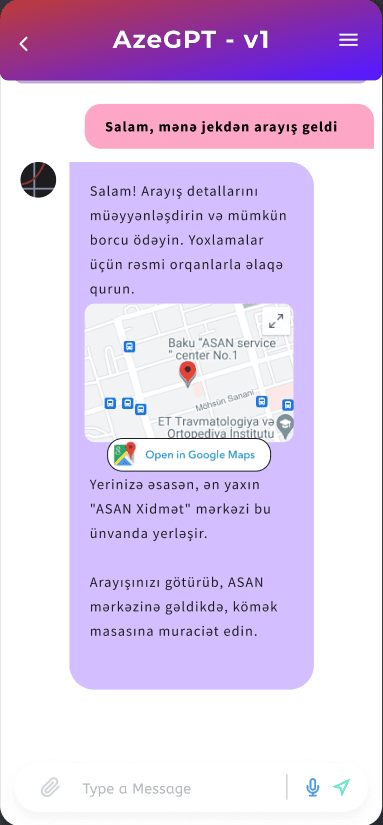
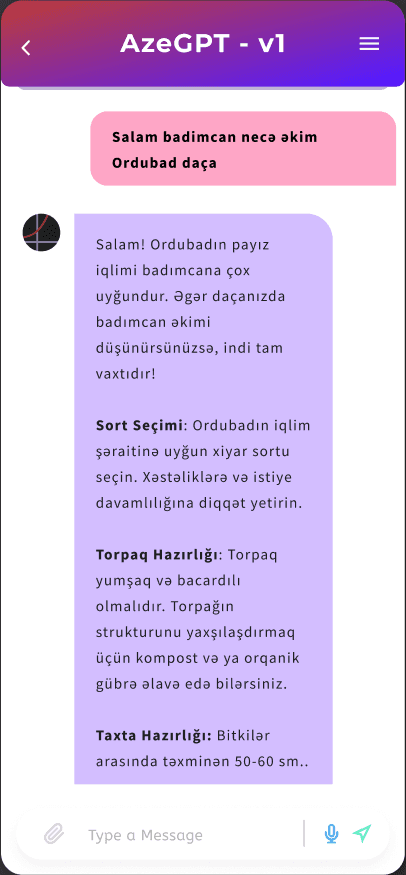
Examples Use Cases:
How can you use an Azeri LLM?
Here are some scenarios:


©NurAI Labs 2025
Ignis Ex Machina